Kafka Getting Started - Kafka Series - Part 2
Kafka Getting Started - Kafka Series - Part 2
This is part two of Kafka series. if you want to learn how Kafka works and Kafka architecture. Read here Kafka Architecture.Kafka Getting Started - Kafka Series - Part 2
In this article, we will see how to configure Kafka locally and run the Kafka server.
Kafka node Setup
Firstly, On a single machine, a 3 broker Kafka instance is at best the minimum, for a hassle-free working. Also, the replication factor is set to 2.
Let’s say A, B and C are our Kafka brokers. With replication factor 2, the data in A will be copied to both B & C, the data in B will be copied to A & C and the data of C is copied to A & B.
Prerequisites
- java >= 1.8 installed in the machine
- Set java environment in the machine. Environment Setup
- download binary distribution of Kafka here
Setup
Meanwhile, extract the Kafka archive in the convenient place and cd into it. Use the terminal to run the Kafka ecosystem
First we need to run the Kafka ZooKeeper in the Terminal.
What is ZooKeeper?
ZooKeeper used to manage the service discovery and to do the leadership election Kafka Brokers. it sends changes of the topology to Kafka, so each node in the cluster knows when a new broker joined, a Broker died, a topic was removed or a topic was added, etc. it provides an in-sync view of Kafka Cluster configuration.

ZooKeeper Overview
start the ZooKeeper instace with
bin/zookeeper-server-start.sh config/zookeeper.propertiesKafka Broker
- In the Config folder, there would be a server.properties file. This is the kafka server’s config file. We need 3 instances of kafka brokers.
- Make a copy.
$ cp config/server.properties config/server.bk1.properties - In the copied file, make the following changes
broker.id=1 #unique id for our broker instance
listeners=PLAINTEXT://:9093 #port where it listens
log.dirs=/home/neoito/kafka-logs-1 #to a place thats not volatile- Further, make 2 more copies of it with the same process. change the above line with a consecutive number like broker.id=2, broker.id=3
- Finally, Run the individual brokers like
$ bin/kafka-server-start.sh config/server.bk1.properties
$ bin/kafka-server-start.sh config/server.bk2.properties
$ bin/kafka-server-start.sh config/server.bk3.propertiesAfter that, we need to create a topic where Producer can push the records and consumer can subscribe/listen to it.
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topicAbove command will create a topic in the Kafka Broker with a replication factor of 3 with one partition
bin/kafka-console-producer.sh --broker-list localhost:9093 --topic my-replicated-topicthe command will start the producer from the command cli where we can push the records to Kafka Brokers. After that, we need to start the consumer from the cli.
bin/kafka-console-consumer.sh --bootstrap-server localhost:9093 --from-beginning --topic my-replicated-topicit will start the consumer in the port 9093. —from-beginning command will read the records in the topic from the beginning.
That is to say, if we type anything in the producer cli, we can read those records from the consumers command line.
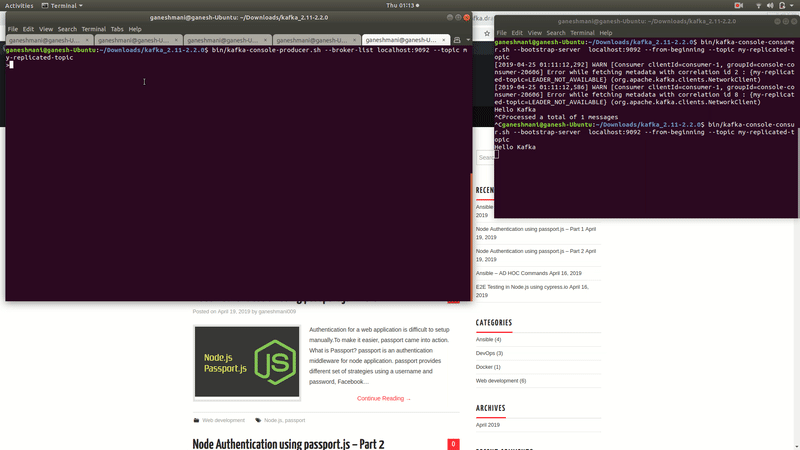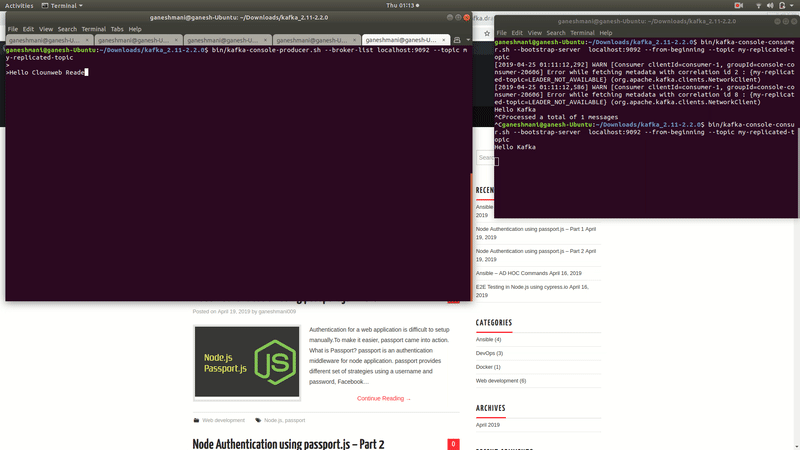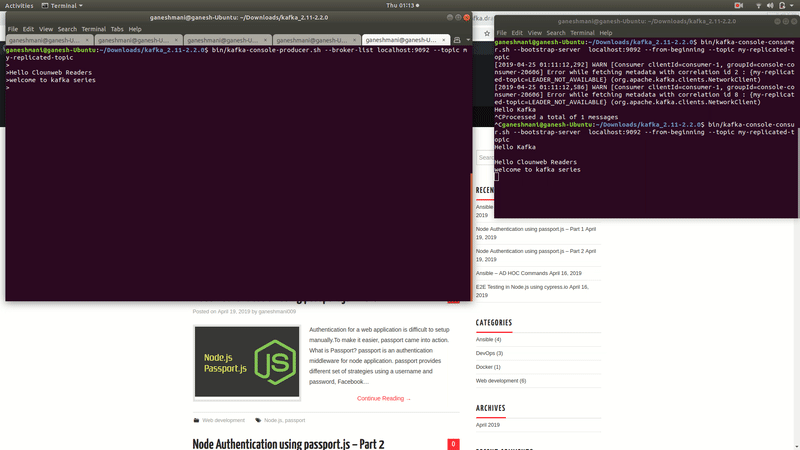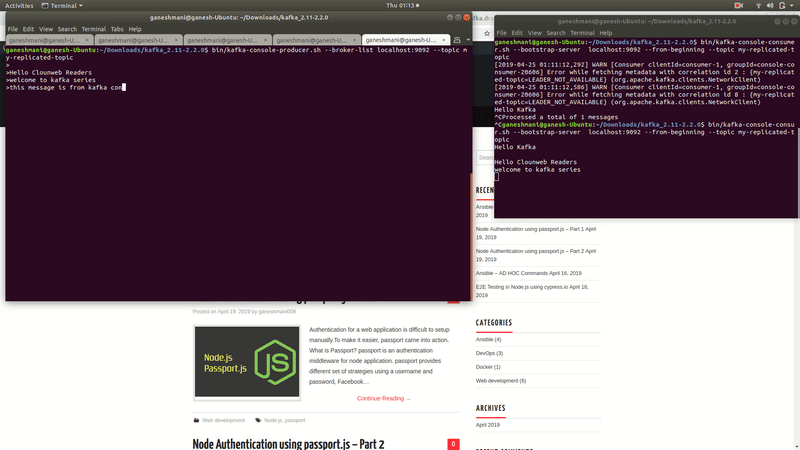
Kafka Demo
In conclusion, we can now subscribe to a topic and listen to the records without losing any data. it will be useful in several scenarios.
we will see how to use Apache Kafka with web application in next blog.Stay tuned!!!!! :-)